
Your Agent Is Still a Hardcoded Workflow. It Is Not a Digital Employee Yet.
The missing layer in enterprise AI is organizational, not just technical.

Why enterprise agents need organizational interpretation, not just documents, tickets, and workflows.
If you think agents do not need to understand how people work inside a company, you are still thinking of agents as tools, not workers.
That was fine when AI mostly answered questions, summarized documents, or helped draft text. In that world, the system stayed at the edge of the organization. It did not need to know who actually makes decisions, which process people avoid, or which escalation path works in practice.
But agents are starting to move from the edge of work into the workflow itself. The moment an agent files a ticket, routes an approval, escalates an issue, or hands work to another person, it is no longer just producing output. It is acting inside the organization.
And anything acting inside an organization needs some understanding of how that organization actually works.
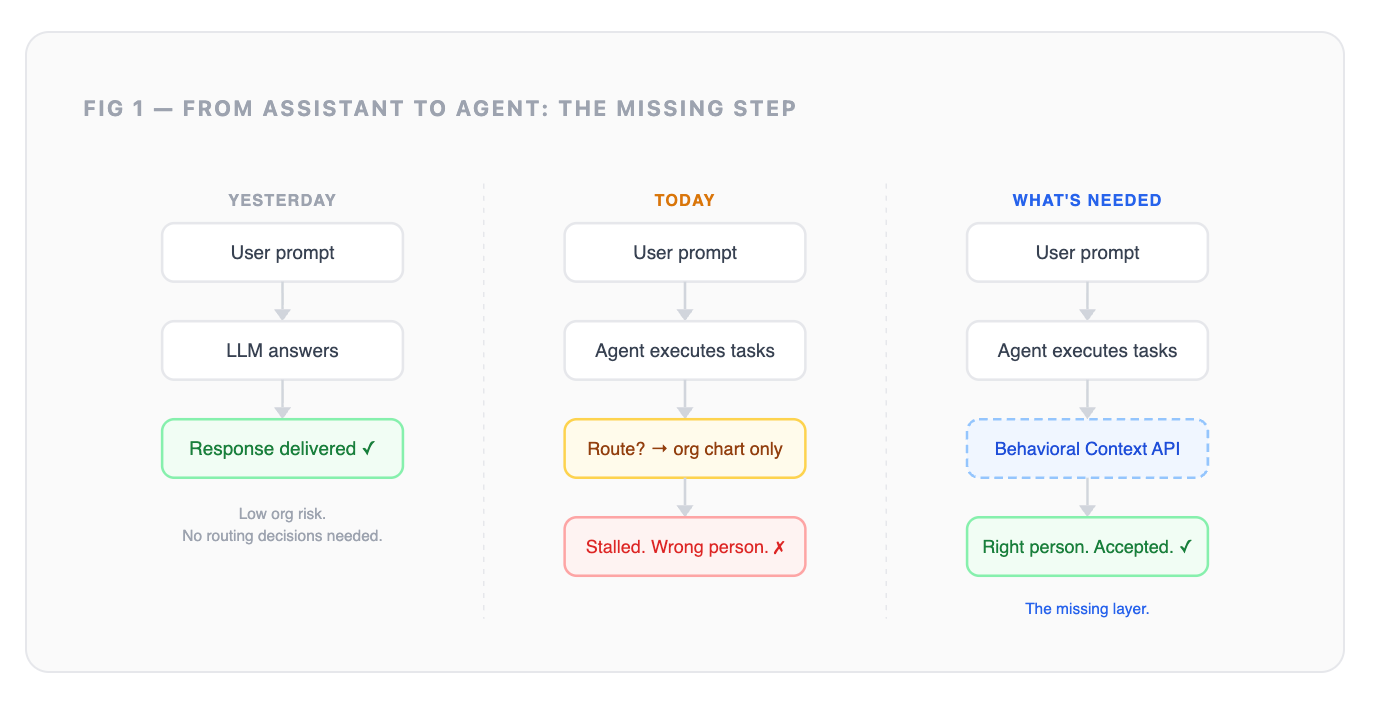
Six months ago, most enterprise AI conversations were still centered on copilots, search, and chat interfaces. The system could answer questions, summarize documents, or help employees draft work. It did not need a deep model of how the organization operated because most of the risk stayed at the interface layer.
That is changing.
AI systems are now being connected to tools, workflows, approvals, tickets, CRM systems, knowledge bases, and internal communication channels. They are no longer just answering questions. They are starting to participate in work.
And the next version every platform team is building toward is not just an assistant that responds to prompts. It is an agent that behaves more like an employee: knowing who to involve, when to escalate, which channel actually gets a response, and who the real decision-maker is regardless of what the org chart says.
A new hire learns this over their first three to nine months. They make a few wrong calls, observe how work actually moves, and build an informal map of the organization. That map is almost never the same as the onboarding deck. By the end of that window, both the company and the person know whether there is a real fit.
Agents do not get three to nine months. They do not naturally observe the organization the way people do. They only see the context and permissions we give them.
So if enterprises want agents that can navigate organizations reliably, they need to give those agents what people gradually build for themselves: a working model of how the organization actually operates.
That is the gap.
And it is not just a model problem. It is an infrastructure problem.
The capture thesis is right, and it is not enough
YC’s Request for Startups #15 “The AI Operating System for Companies,” points in the right direction: capture meetings, tickets, customer interactions, and operational signals to build an operational map of the company.
Good instinct. If you instrument what happens inside an organization, you can see far more than a static org chart or document repository ever reveals.
But capture is not the same as understanding.
Jira can tell you a ticket was assigned, delayed, reassigned, blocked, or completed. It cannot tell you whether the assignee actually owned the work, quietly handed it off, waited for someone with informal authority, or completed something nobody downstream trusted.
Calendar can tell you a meeting happened. It cannot tell you who had real decision authority in the room, who was invited for political cover, who stayed silent but controlled the outcome, or whether the real decision happened afterward in a private conversation.
Slack can show who responded, who was mentioned, and which channels were active. It cannot automatically tell you whether people trusted the answer, avoided conflict, escalated informally, or routed around a broken process.
The most important organizational signals often show up in the gaps: what was delayed, avoided, rerouted, silently escalated, or left unowned. And even when the activity is fully captured, the meaning is still ambiguous.
A person is copied on 200 emails a day, invited to 30 meetings, partially joins many of them, appears in the notes, but rarely speaks. What does that mean?
Are they a real decision-maker? A political observer? A bottleneck? A passive stakeholder? A compliance checkbox? A senior person everyone includes to reduce risk? Or just someone with the same title as five other people who behave completely differently?
The logs can show activity. They do not explain authority.
And authority is only one layer. The same behavior can mean different things depending on company culture, team culture, personal work style, attention patterns, and how others perceive that person.
AI may know how someone presents themselves through their messages, calendar, documents, and meeting behavior. But it does not automatically know how others perceive them. It may know what a team produces, but not whether other teams experience that team as trusted, slow, political, overloaded, strategic, or hard to work with.
A good employee learns these things quickly. They learn who actually owns a decision, who is copied for political cover, who gets included because they matter, who gets included because people are afraid to exclude them, which team is trusted, which process everyone avoids, and which escalation path works in practice.
That is what it means to navigate a company well.
So if we want agents to become digital employees and not just workflow executors, shouldn’t they understand the same things?
The harder layer is not capture. It is interpretation. Specifically: interpreting what did not happen, what was rerouted, what was avoided, what nobody wrote down, and what behavior actually means inside that organization.
Every serious enterprise AI stack is getting better at retrieval. Almost none of them are solving this layer.
There are three layers of enterprise context. Everyone is building the second one.

When an agent routes a decision, it is not doing a search. It is asking an organizational question: who actually owns this, who is trusted, who has bandwidth, and what escalation path will be accepted?
Some of this may be documented. Most of it is learned through behavior.
This evolved from people analytics, but it is not where people analytics ends
Traditional people analytics measures individuals and teams for human decision-making: performance, attrition risk, engagement, skills, workforce planning. Useful for HR leaders. Important for management.
But agents need a different kind of organizational intelligence.
They do not need a quarterly dashboard telling a CHRO which teams are disengaged. They need runtime context: how work actually flows, where decisions bottleneck, which trust networks are real, who holds informal authority, and what route is likely to work in this specific situation.
Same roots. Different unit of analysis. Different buyer. Different output.
People analytics helps humans understand the workforce. A behavioral context layer helps AI systems navigate the organization.
There is a fair criticism here: people analytics has been promising to make organizational behavior measurable for years, and the track record has been mixed.
But the timing is different now.
For decades, people debated whether AI could become intelligent enough to reason about work. At the same time, people analytics was trying to measure organizational behavior, mostly for human dashboards, HR decisions, and periodic management review. The output was usually a report, a score, or a dashboard someone had to interpret.
Generative AI changes the use case.
Now the system is not just helping a human analyze the organization. The system itself is trying to act inside the organization. It needs context at the moment of action: who to route to, when to escalate, whether a path is risky, and when the workflow is ambiguous enough to require human judgment.
That is why this is not simply “people analytics again.”
People analytics tried to help humans understand organizations. Behavioral context helps AI operate inside them.
The old promise was measurement. The new requirement is runtime interpretation.
Passive signal is not trust
The signal distinction matters. Most teams conflate three different things: passive ONA, active ONA, and broader organizational behavior.
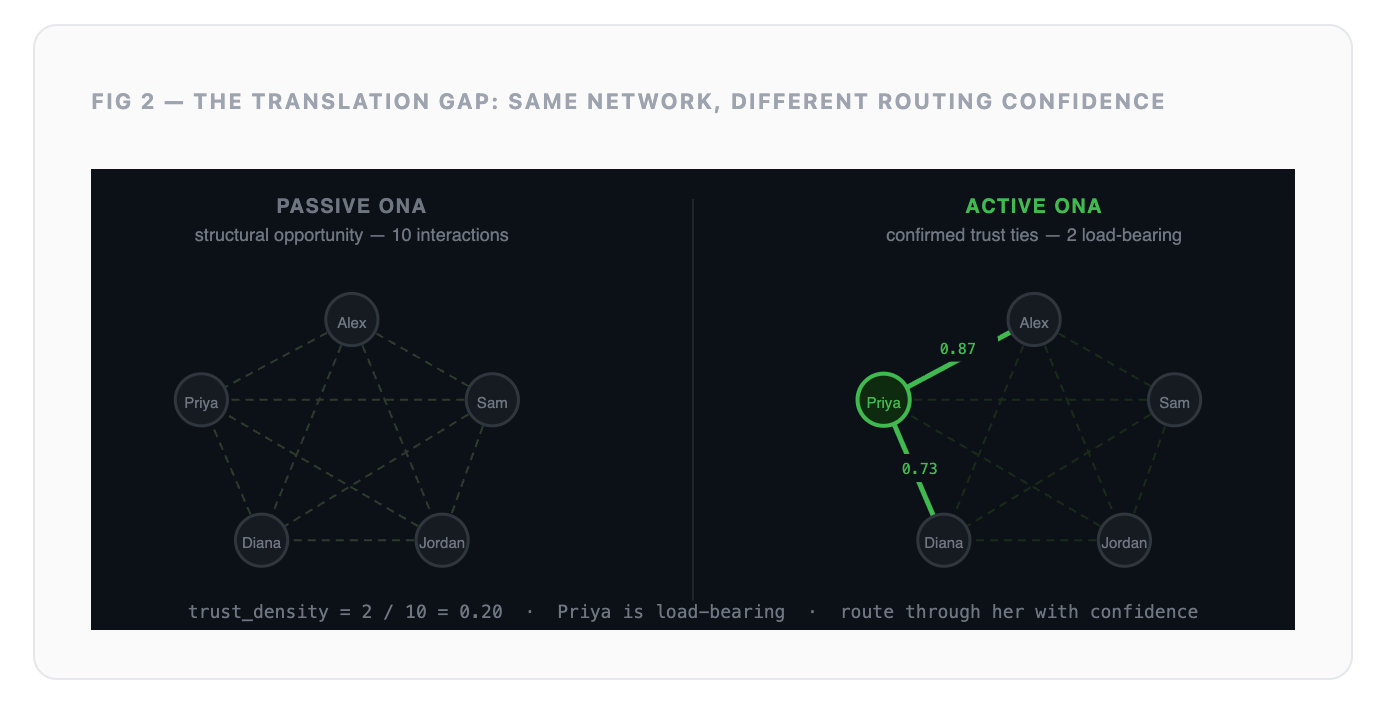
Passive ONA is digital exhaust: meeting co-attendance, calendar patterns, ticket routing, response times, approval flows, and other interaction traces. It shows the structure of work: who has the opportunity to interact, where work moves, and where it slows down.
Active ONA is relational signal: confirmed trust ties, peer-recognized expertise, reliance patterns, psychological safety indicators, and feedback on who people actually go to for help or decisions. It shows the meaning of those interactions: whether information is trusted, acted on, ignored, or avoided.
But organizational behavior goes beyond passive and active ONA. It also includes cultural and behavioral patterns: how open the company is, how comfortable people are challenging decisions, whether teams escalate early or hide problems, whether authority is centralized or distributed, whether people avoid conflict, and how much discretion employees actually have in practice.
The mistake is treating high passive signal as high trust.
Two people can be in every meeting together and never genuinely rely on each other. A ticket can be assigned to someone who informally reroutes it every single time. A senior person can be copied on every thread and still not be the real decision-maker.
Frequency is not trust. Co-attendance is not influence. Visibility is not authority.
And the same signal can mean different things in different cultures. A dense meeting cluster in one company may signal strong collaboration. In another, it may signal over-coordination, politics, or low trust. A quiet employee in one culture may be disengaged. In another, they may be a respected expert who only speaks when necessary.
So the signal is not just who interacts with whom.
It is how those interactions are interpreted inside that specific organization.
Making organizational behavior computable
This is what my Columbia research focused on through the Organizational Intelligence Loop, or OIL framework.
Over the past five years, my team and I have been researching how to turn organizational behavior into measurable, machine-readable signals, using more than 1B behavioral signals across hundreds of companies.
After publishing the research, we built an organizational behavior graph: a system that maps how work actually moves through a company, including trust, influence, escalation, ownership, response patterns, and informal authority.
Then we trained that graph into a model.
The goal is to make organizational dynamics computable. Not by reducing people to simple scores, but by translating patterns of behavior into context AI can reason over.
Company culture, team norms, trust networks, decision bottlenecks, and informal power are usually treated as “soft” organizational knowledge. But with enough behavioral signal, they can become structured inputs: measurable, comparable, and usable by AI systems at runtime.
This is similar in spirit to how large-scale language models learn from patterns in language. Behavior is not language, but organizational behavior also has recurring structures: who routes to whom, who is trusted for what, where decisions stall, which teams avoid each other, and which people become load-bearing nodes.
That is what we are introducing at BehaviorGraph: an organizational behavior model that gives enterprise AI systems the missing context layer they need to navigate companies.
But machine-readable does not mean perfectly understood.
Organizational behavior is contextual. Any model of it will be lossy, just like models of language, fraud, credit risk, customer intent, or medical risk are lossy. The point is not to create perfect truth. The point is to do better than the current baseline: org charts, static workflows, document mentions, and hard-coded routing.
A metric like Trust Density, for example, should not be treated as a complete measure of trust. It is a computable proxy for relational reliability inside a specific workflow context.

The question is not whether one metric perfectly represents trust. It is whether behavioral signals improve routing, escalation, and risk detection compared with title-based or workflow-based systems.
The product is not the raw data. The product is the trained interpretation of what organizational behavior patterns actually mean, with confidence levels, boundaries, and escalation rules. For more examples, check out this article.
This does not mean turning informal dynamics into fixed rules. The model should surface patterns without freezing them into permanent hierarchy. Informal dynamics are fluid, contextual, and sometimes useful precisely because they are not formalized.
The goal is not to let agents autonomously codify office politics. The goal is to give both humans and agents better options: likely routes, confidence levels, risk signals, and clear moments where human judgment is required.
There is another problem: historical truth
Engineers often assume that if the AI has all the documents, tickets, meeting notes, and version history, it can reconstruct what happened.
But organizational history is not that clean.
The latest document may not be the most accurate one. The most official version may have been written after the politics changed. A decision record may say one thing, while the real compromise happened across three side conversations that were never documented. A project postmortem may describe the failure, but not the moment in the middle when ownership broke, trust collapsed, or the wrong person became the bottleneck.
Even if you rank everything by date, you still do not know where the truth drifted.
This is why knowledge management has always been harder than storage. KM is not just about preserving information. It is about provenance, context, interpretation, and knowing which version of reality people actually acted on.
It is like correcting history books. You do not find truth by simply collecting every document. You ask: who wrote this, when, for what audience, under what incentive, with what missing context, and how did other people behave around it?
That is also what enterprise AI needs.
If an engineer thinks, “I have all the papers, so I do not need to understand people,” I would tell them to study Knowledge Management 101.
Because organizations do not run on documents alone. They run on interpreted knowledge, social trust, incentives, memory, and behavior.
What about governance, permissions, and sensitive data?
he obvious objection is: isn’t this sensitive?
Yes. Organizational behavior data is sensitive.
But sensitivity does not mean the category should not exist. It means the system has to be designed with the right governance, permissions, privacy boundaries, auditability, and deployment controls.
Workday handles sensitive employee data. 1Password handles sensitive credentials. Banks handle sensitive financial data. Apartment applications handle income, identity, and background information. Companies still use them because the value is necessary and the systems are expected to meet a higher bar for security and trust.
That said, this category has its own risk model. A behavioral graph is not the same as a password vault or HR record system. It can reveal inferred patterns of trust, authority, bottlenecks, avoidance, and informal influence. That means the governance bar has to be higher — It should not become a searchable political map of the company; It should not become a manager dashboard for spying on employees; It should not reduce people into simplistic scores.
The safer architecture is task-bounded and permissioned.
An agent asks a narrow runtime question. It receives only the minimum context needed for that task. The output is permission-aware, policy-aware, and auditable. When confidence is low or the situation is sensitive, the system escalates to a human instead of pretending the workflow is clear.
Used correctly, behavioral context keeps humans in the loop. It helps agents avoid obvious routing mistakes, and it helps humans see where the real organizational problem is: unclear ownership, broken escalation paths, low trust, overloaded teams, or workflows that no longer match reality.
Once humans have that visibility, they can decide what to do: clarify ownership, redesign the workflow, add review steps, adjust permissions, create a new escalation path, or keep the ambiguity human-led.
This is not about ignoring governance or bypassing permissions. It is about working on top of them.
An AI agent should not see everything. It should only access the organizational context it is allowed to use, for the task it is performing, under the policies of that company.
But within those boundaries, agents need a certain level of discretion, just like employees do. A normal employee does not operate only by reading the org chart and following static workflows. They make judgment calls: when to ask for approval, who to involve, when to escalate, and when a situation is sensitive enough to require extra verification.
That is the goal: not unlimited autonomy, not surveillance, and not private individual-level exposure.
Bounded, permissioned organizational context.
The right architecture is not “give AI all the data.” It is to give AI the minimum governed context it needs to act responsibly inside the organization, with permission controls, audit trails, confidence levels, and clear boundaries.
Sensitive data can be handled responsibly when the system is built for it. That is the bar this category has to meet.
What agents actually need at runtime
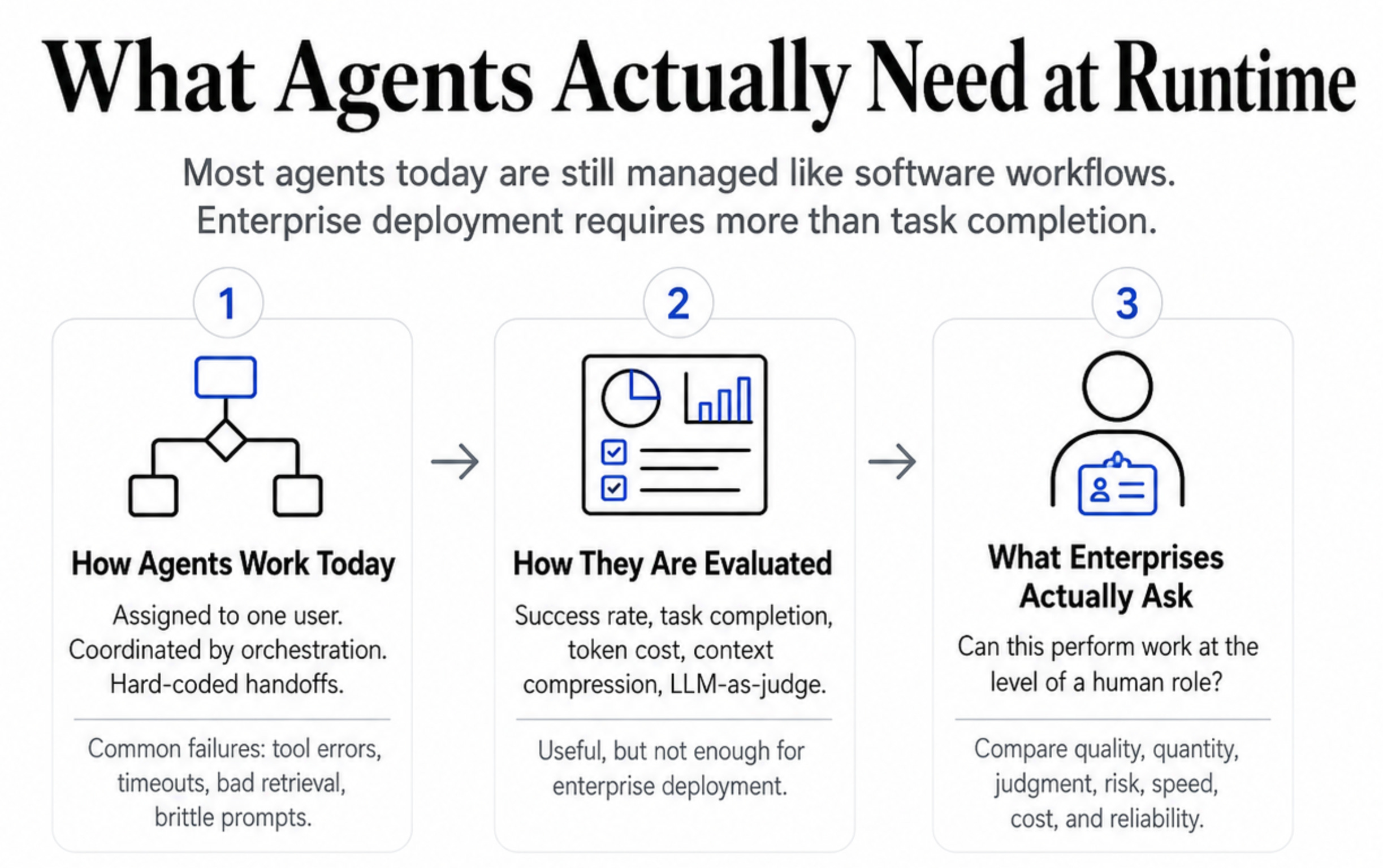
Most agents today are still managed like software workflows. They are assigned to one user, coordinated by an orchestration layer, or routed through hard-coded paths between tools, humans, and other agents. Even before organizational complexity shows up, they can fail for basic reasons: tool errors, timeouts, bad retrieval, brittle prompts, unclear permissions, context loss, or poor handoff design.
That is why most agent evaluation still looks like software evaluation: success rate, task completion, token cost, context compression, and LLM-as-judge scoring.
These metrics are useful. But they are not enough for enterprise deployment.
Enterprises do not only ask whether an agent completed a task. They ask whether the agent can perform work at the level of a human role. That means comparing agents against human work on quality, quantity, consistency, judgment, risk, speed, cost, and operational reliability.
For an individual experimenting with agents, spending $2,000 a month on marketing automation may sound expensive. But for an enterprise, the comparison is not whether the cost can be reduced to $1. The comparison is whether the agent can replace, augment, or scale work that would otherwise require a human team.
In real companies, doing the job is not just producing output.
A good employee knows when to ask for approval, who needs to be involved, which stakeholder may block the work, which channel will get a response, which decision is politically sensitive, and when the official process is not the real process.
Today’s agents usually do not know that. They are routed through system prompts, workflow rules, or org chart lookups. That can work for narrow demos, but hard-coded coordination paths break when teams change, responsibility is ambiguous, or the agent needs to hand work off across functions.
This is where the agent orchestration problem becomes a routing problem. An agent finishes a task and needs to hand it off to a person, another agent, an approval authority, or the next workflow step. That handoff is where enterprise AI moves from task execution into organizational navigation.
Current frameworks can usually answer who is assigned in the workflow, who owns the system, who appears in the org chart, or who was mentioned in a document. But they usually cannot answer who is the right person for this right now, given actual expertise, current load, informal authority, trust relationships, and whether the organization will accept that route.
Agents do not just hallucinate facts. They can hallucinate authority, routing, ownership, and organizational exposure.
If an agent sends a sensitive approval to the wrong person, escalates through the wrong path, or bypasses the real decision-maker, the failure is not just technical. It becomes visible inside the organization and erodes trust quickly.
So the real enterprise question is not only: did the agent complete the task?
It is: did the agent complete the work in a way the organization would accept?
That requires runtime organizational judgment, not just retrieval or orchestration. Whether enterprises use RAG, agents, MCP, workflow automation, or whatever architecture comes next, the problem is the same: AI systems need organizational context to act inside companies.
Behavioral context does not mean agents should act autonomously in every ambiguous situation. Often the value is the opposite: helping an agent recognize ambiguity and escalate instead of pretending the workflow is clear.
Execution layers help AI take steps. Behavioral context helps AI navigate the company.
Right now, almost none of them have that layer.
The last point
A lot of people in AI believe AGI is coming.
But intelligence does not operate in a vacuum.
Humans navigate the world partly by sensing how others perceive them, whether that perception is accurate or not. That perception changes how we speak, who we ask, when we push, when we wait, and when we escalate.
Inside companies, that social awareness is not decoration. It is part of how work gets done.
If we want AI to become more than a tool, if we want it to act like a real digital employee, it cannot only know what is written down. It has to understand the organizational reality people respond to every day: trust, reputation, authority, avoidance, attention, and the invisible paths through which decisions actually move.
A knowledge graph tells AI what the company knows.
An organizational behavior graph gives AI the organizational judgment it needs to act like a good employee.